У цій статті ми продовжимо дослідження текстів передвиборчих програм кандитатів у Президенти України. Із попередньою статтею можна ознайомитись тут.
Отже, у попередній статті ми визначили певну кількість слів, які найчастіше повторюються у текстах передвиборчих програм. І засумували, оскільки серед найуживаніших слів знову побачили знайомі «влада», «забезпечити» та інші. Ці слова або взагалі ніякого змісту не несуть, або попереджають про можливість реакційних заходів. Тобто ми боїмось — що держава буде «забезпечувати» собі «владу», нехтуючи при цьому ідеалами Майдану.
Щоб дослідити взаємозв’язок слів у текстах нами було використано два методи: власне метод текстового аналізу (Text Mining - TM) та методики аналізу соціальних мереж (Social Network Analysis - SNA). Методи TM використовувались для кластеризації масиву слів (ми узяли найбільш уживаніші слова). Методики SNA використовувались для побудови графа взаємозв’язків слів у повній сукупності тексту. Тут нами також було використано обмежену кількість найпопулярніших слів. Як і у всіх інших наших дослідженнях — аналіз проводився з використанням виключно засобів програмного середовища R.
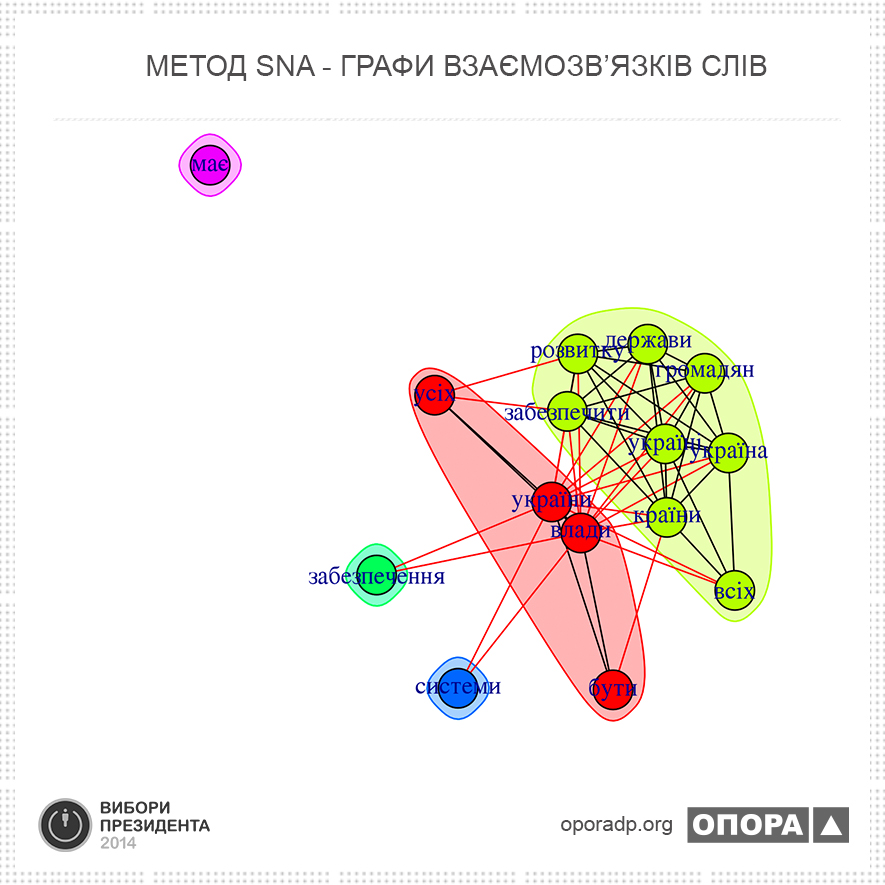
Розгляд почнемо з методів SNA. Граф взаємозв’язків слів приведений нижче. Окрім власне слів, на рисунку зображені границі груп, які були виділені в процедурах аналізу.
Власне, наведений рисунок можна і не коментувати — взаємне розташування слів говорить за себе все. Радість приносить факт близького розташування на графіку (а в текстах — сильної взаємодії) слів «розвитку», «держави», «громадян».
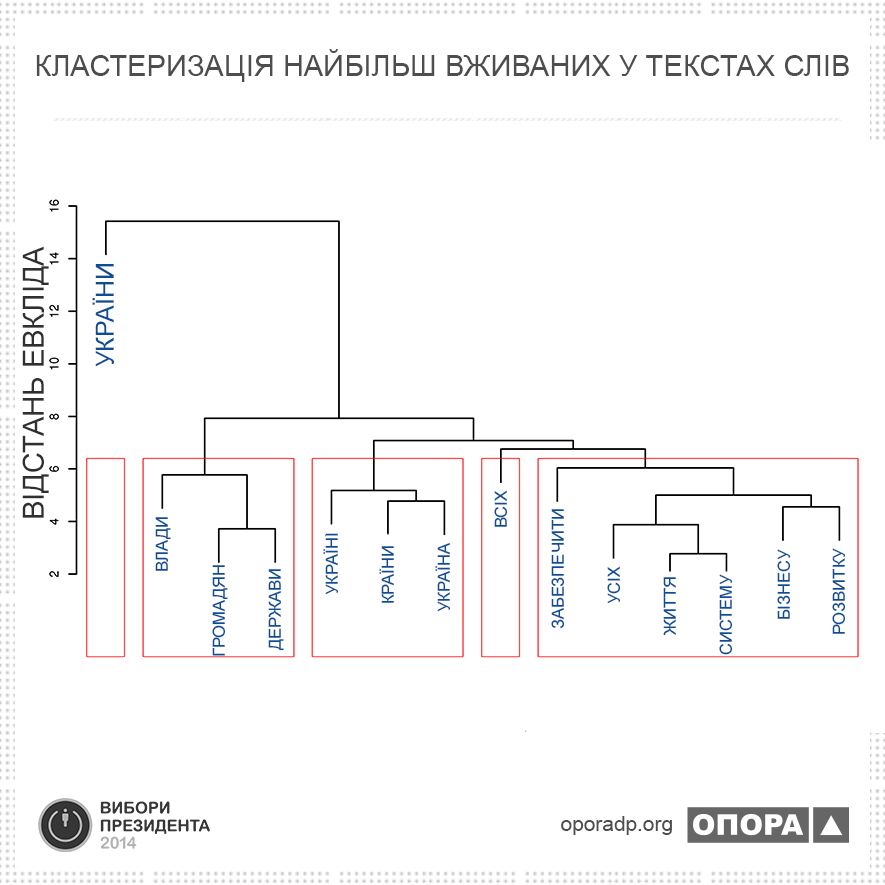
При кластерному аналізі в якості метрики використано відстань Евкліда, в якості алгоритму кластеризації — метод Варда. В результаті у нас вийшла наступна картина:
Червоними прямокутниками ми виділили окремі кластери, які (на нашу думку) найбільш точно ув’язуються із семантичними характеристиками текстів. Зверніть увагу на доволі віддалене положення слова «України». Це свідчить про те, що це слово вставляється всюди, де тільки можна.
Але наявна інформація дозволяє зробити ще один варіант аналізу: за текстами виокремити групи кандитатів. Щось подібне ми зробили у попередній статті, коли обчислювали коефіцієнт Охаі. Але тоді робилось попарне порівняння. Зараз ми зробимо багатовимірний аналіз.
Щоб згрупувати кандидатів ми транспонували матрицю слів, поставивши у назви стовпців власне слова, а в назви рядків — прізвища кандидатів. Дендограму кластерного аналізу зображено нижче.
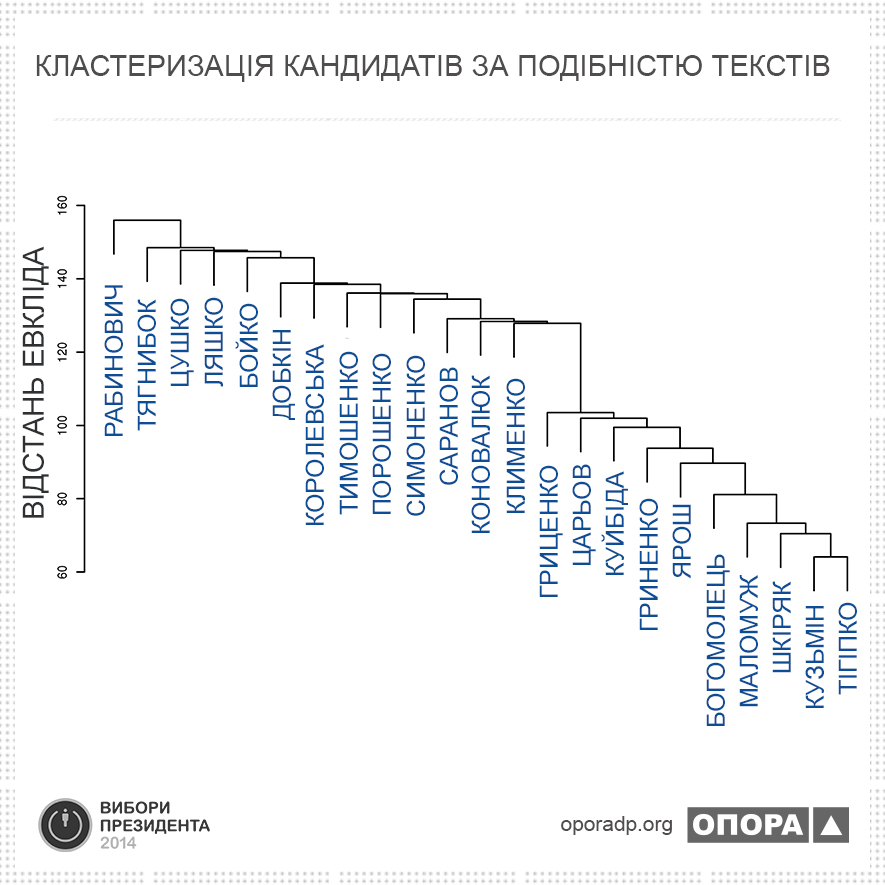
Хоча дендограма має дещо незвичний вигляд, на ній можна зафіксувати два типи кластерів. Ці типи відрізняються «як небо і земля» у прямому розумінні цієї фрази. На нашу думку — кластери верхньої групи — це найбільш «пухкі» та літературні тексти передвиборчих програм. Нижня група — прості тексти, написані у стилі «звіту з поля бою».
Таким чином, можна констатувати різний ступінь «літературної підтримки» кандидатів у Президенти з боку їхнів PR-служб.